Analisis optimasi jalur pemrosesan data pada slot
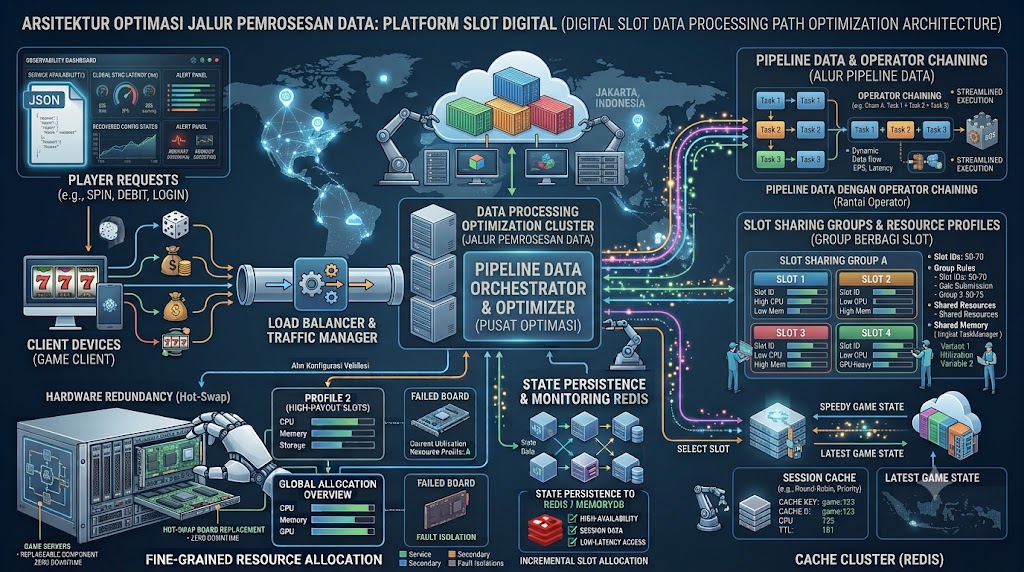
Dalam arsitektur platform slot digital modern, efisiensi jalur pemrosesan data menjadi faktor penentu utama performa sistem. Setiap putaran, transaksi, dan pembaruan status harus mengalir melalui serangkaian tahapan pemrosesan dengan latensi minimal dan throughput maksimal. Memahami mekanisme optimasi pipeline ini penting bagi pengembang dan pengelola platform untuk merancang sistem yang skalabel dan responsif. Berikut artikel ini akan membahas tentang Analisis optimasi jalur pemrosesan data pada slot.
Memahami Konsep Slot sebagai Unit Alokasi Pemrosesan
Dalam sistem pemrosesan data terdistribusi, konsep “slot” merujuk pada unit dasar alokasi sumber daya komputasi. Apache Flink, misalnya, mendefinisikan slot sebagai unit penjadwalan di mana setiap TaskManager membagi memorinya menjadi beberapa slot yang dapat mengeksekusi tugas secara paralel . Slot tidak mengisolasi CPU, hanya memori, sehingga memungkinkan beberapa tugas berbagi sumber daya dalam satu JVM.
Untuk platform slot, pemahaman tentang slot komputasi ini sangat penting karena setiap permintaan spin membutuhkan alokasi sumber daya yang presisi. Dengan membagi kapasitas pemrosesan ke dalam slot-slot yang terdefinisi, sistem dapat mengelola beban kerja secara lebih terukur dan efisien.
Operator Chaining untuk Mengurangi Overhead
Salah satu strategi optimasi paling fundamental dalam pipeline pemrosesan data adalah operator chaining atau penggabungan operator. Dalam Flink, operator-operator yang memenuhi syarat dapat digabung menjadi satu tugas yang berjalan dalam thread yang sama . Pendekatan ini memberikan beberapa keuntungan signifikan.
Penggabungan operator mengurangi thread switching karena tugas dalam satu chain tidak perlu berpindah antar thread, mengurangi overhead konteks. Selain itu, data antar operator dalam satu chain tidak perlu diserialisasi dan dikirim melalui jaringan, menghilangkan biaya serialisasi dan deserialisasi. Tidak adanya antrian buffer antar operator yang saling terhubung dalam chain juga mengurangi kebutuhan buffering.
Untuk platform slot, ini berarti pipeline yang menangani alur data dari penerimaan permintaan spin hingga pencatatan hasil dapat berjalan dengan overhead minimal. Syarat pembentukan chain meliputi kesesuaian paralelisme, tidak adanya shuffle data, dan kebijakan chaining yang diizinkan .
Slot Sharing Group untuk Optimasi Resource
Flink memperkenalkan konsep SlotSharingGroup untuk mengoptimalkan penggunaan sumber daya. Secara default, semua tugas dari job yang sama dapat berbagi slot . Pendekatan ini mengurangi jumlah slot yang dibutuhkan karena jumlah slot yang diperlukan sama dengan paralelisme tertinggi, bukan total paralelisme semua tugas.
Selain itu, tugas yang ringan dapat berbagi slot dengan tugas yang lebih berat, mengurangi pemborosan sumber daya . Untuk platform slot, ini memungkinkan alokasi sumber daya yang efisien di mana sumber daya dan sink dengan paralelisme berbeda dapat tetap berbagi slot secara optimal .
Fine-Grained Resource Management
Pendekatan yang lebih canggih dalam optimasi pipeline adalah fine-grained resource management, di mana slot tidak lagi seragam tetapi memiliki profil resource yang berbeda-beda . Dalam model ini, aplikasi dapat menentukan resource yang dibutuhkan untuk setiap SlotSharingGroup .
Parameter yang dapat dikonfigurasi meliputi CPU cores yang menentukan jumlah core yang diperlukan, task heap memory untuk alokasi memori heap, task off-heap memory untuk memori di luar heap, managed memory untuk operasi terkelola, dan external resources seperti GPU . Untuk platform slot, ini berarti layanan kritis seperti Game Engine dapat dialokasikan dengan CPU dan memori yang lebih besar, sementara layanan pendukung seperti Analytics dapat menggunakan profil resource yang lebih kecil.
Optimasi Penjadwalan dan Load Balancing
Penelitian tentang load balancing berbasis tabu search pada Flink menunjukkan bahwa optimasi penjadwalan dapat menurunkan latensi komputasi rata-rata sebesar 10–20 ms dan meningkatkan throughput sekitar 15% . Pendekatan ini membangun model performa node dan menggunakan algoritma pencarian untuk menentukan jalur penjadwalan optimal.
JobManager bertanggung jawab untuk menjadwalkan tugas ke TaskManager yang tersedia dengan mempertimbangkan ketersediaan resource, dependensi tugas, dan paralelisme yang diinginkan untuk mencapai distribusi optimal . SlotAllocator berperan dalam menghitung kebutuhan resource dan memetakan vertex ke slot yang tersedia .
Optimasi Broadcast Variable untuk Pengurangan Overhead Jaringan
FLIP-5 mengusulkan optimasi broadcast variable untuk mengurangi overhead jaringan dengan mendesain ulang mekanisme distribusi data . Pendekatan ini memungkinkan satu subpartition per TaskManager menerima broadcast data, bukan satu per slot, mengurangi jumlah transmisi data yang berulang .
Data kemudian disimpan di area memori bersama tingkat TaskManager dan dapat diakses oleh semua task tanpa transfer jaringan berulang . Hasil eksperimen menunjukkan bahwa pendekatan ini menjaga waktu pemrosesan tetap stabil (6-7 detik) bahkan ketika jumlah slot per TaskManager meningkat dari 1 menjadi 16 .
Kesimpulan
Optimasi jalur pemrosesan data pada platform slot membutuhkan pemahaman mendalam tentang mekanisme alokasi slot, strategi chaining, dan dynamic resource management. Dengan menerapkan operator chaining untuk mengurangi overhead komunikasi, slot sharing group dan fine-grained resource management untuk alokasi presisi, serta load balancing berbasis algoritma optimasi, platform slot dapat mencapai pipeline pemrosesan data yang efisien dan responsif. Investasi dalam optimasi ini akan memberikan dampak langsung pada latensi pemrosesan, throughput sistem, dan pada akhirnya, pengalaman pengguna.
Related Post

Slot dengan fitur gamble untuk menggandakan kemenangan
Fitur ini memberikan kesempatan kepada pemain untuk menggandakan kemenangan mereka melalui mini game tambahan setelah [...]
Slot bernuansa hutan hujan ajaib
Di tengah keheningan alam yang diselimuti kabut lembut, Slot bernuansa hutan hujan ajaib yang membawa pemain [...]